Super sprint
This is the log of the final sprint to the end of the semester, and the end of the capstone project. During this week, I set up the project at the Capstone show exhibit. This was the first test run I had and the foremost opportunity to see the code fly (and crash).

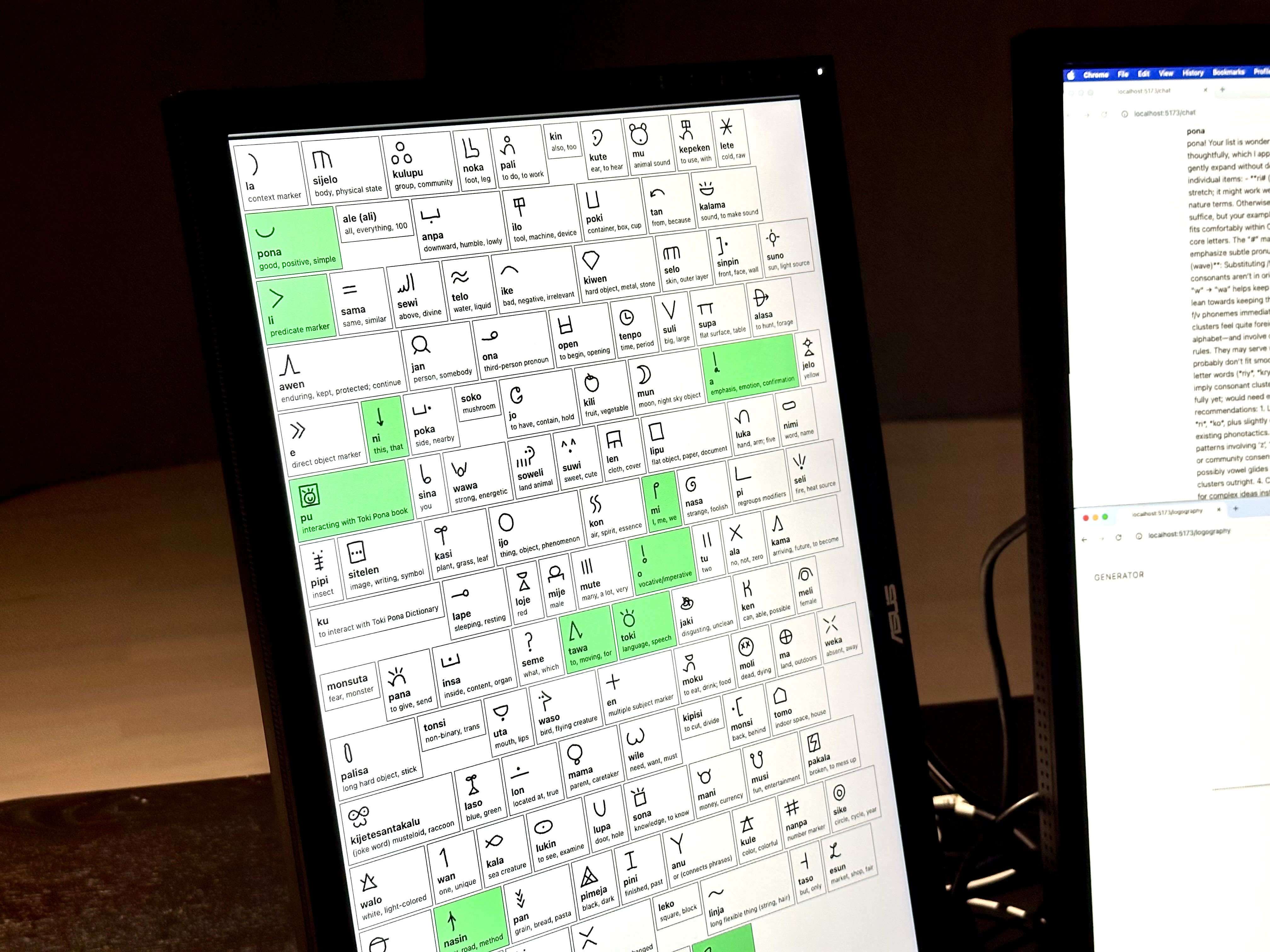
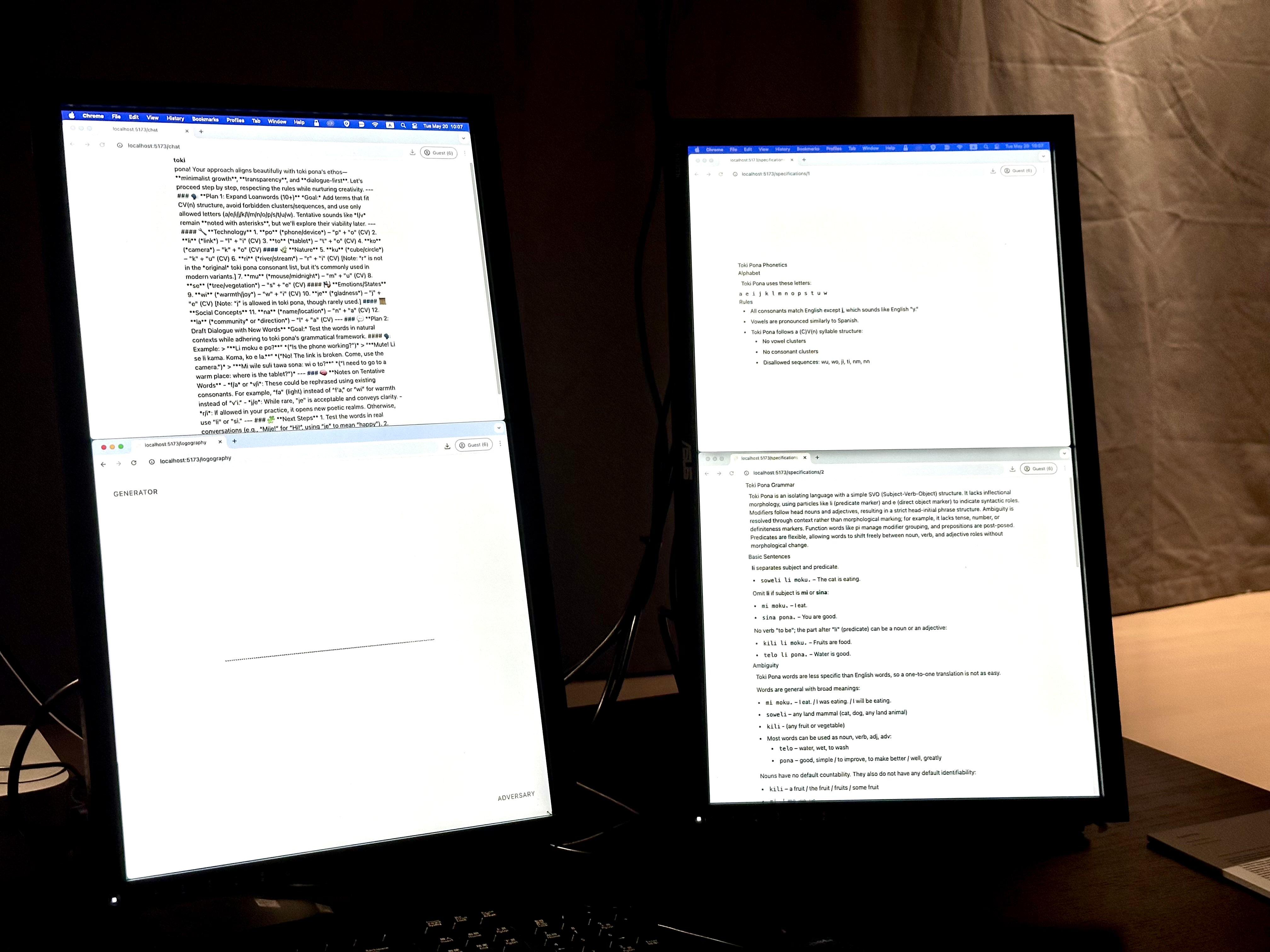
For my setup, I decided to use three monitors all oriented in portrait mode. in a semi-circle configuration.

I was able to acquire a Mac Studio M2 Ultra from Professor Moon, which I used for running a local Ollama instance with Qwen3:30b. I hung the cabling from the top because I liked the “wired-in” aesthetic.


Fixing the procedure
The procedure implementation I had created was a little buggy because of the syncrhonization issues that I was encountering. For example, a procedure would not reiterate when it was queued and executed. Another issue was that the procedure job would count a command as an exchange, which should not be the case. An exchange is only between an agent and an agent.
Waitgroups
While developing this project, I improved my understanding of go routines and waitgroups. Waitgroups are used to synchronize the execution of multiple concurrent operations. What this means is that the programmer has the ability to ensure that even when concurrent operations are running, such as three functions executed at different times, the program will wait for all of their executions to complete before continuing further execution.
For this project’s purposes, this is important when sending commands to agents and keeping a procedure adhere to the way it was written in code procedurally.
I implemented waitgroups in the SendCommandBuilder function, which builds a function that will send a command to agents.
func SendCommandBuilder( ctx context.Context, pool chan<- *chat.Message,) func( []*ChatClient, ...MessageFor,) { return func( clients []*ChatClient, commands ...MessageFor, ) { for _, c := range clients { var wg sync.WaitGroup wg.Add(1) go func(c *ChatClient) { defer wg.Done() var wg2 sync.WaitGroup select { case <-ctx.Done(): return default: for _, cmd := range commands { wg2.Add(1) _ = utils.SendWithContext(ctx, pool, cmd(c)) wg2.Done() } } wg2.Wait() }(c) wg.Wait() } }}The waitgroup code is highlighted above. Essentially, whenever we want to spawn concurrent processes, we must also call Add(1) on the waitgroup to signify that we’d like to wait for a new process. defer wg.Done() is used to signify that when the process is complete, tell the waitgroup that it is completed. the Wait() calls happen later on in the code. These are calls that will not continue the code that is executed after it until only after all the processes in the wait group have finished (i.e. a “blocking call”).
The SendWithContext function is a helper function to send a value with a context to a channel. It is a wrapper for boilerplate select code. It also accepts any number of callback functions to execute after the send is complete, which is useful for logging or managing state.
func SendWithContext[T any]( ctx context.Context, ch chan<- T, val T, callbacks ...func(),) (err error) { defer func() error { if r := recover(); r != nil { return fmt.Errorf("channel send panic: %v", r) } return nil }()
if ch == nil { return fmt.Errorf("channel is nil") }
select { case <-ctx.Done(): return ctx.Err() case ch <- val: if len(callbacks) > 0 { for _, f := range callbacks { f() } } return nil }}These two functions keep the procedure’s instructions in check and in line. It ensures that when we call commands in procedures, they will be executed in the exact order they were called.
Redefining jobs and procedures
I assumed that the reason why the program was not looping when more procedures were added was because of the queue implementation and the job implementation.
The issue was with the NewQueueFromSlice implementation, which was not doing a deep copy of array-like elements or structs. In Go, copying a struct will not copy data contained in a struct that are maps, arrays, or other structs. These have to be copied manually. This goes the same for maps and arrays that contain non-primitive data types. There are libraries that implement deep copying, but I did not want to deal with that. So I rewrote the job implementation from first principles and defined what jobs and procedures are.
A job is an interface with two methods. A Job is still what it was before:
type Job func(ctx context.Context) error
type job interface { do(ctx context.Context) error time() string}
type jobs = []jobThe do method executes the job. It “does” it. The time method is used to keep track of the amount of time a job takes to execute.
Then I defined a procedure type, which is a struct that implements the job interface:
type procedure struct { name string exec Job elapsed time.Duration}
func (j *procedure) do(ctx context.Context) error { t := utils.Timer(time.Now()) defer func() { j.elapsed = t() }()
err := j.exec(ctx) if err != nil { return err }
return nil}
func (j *procedure) time() string { return j.elapsed.String()}Whenever I want to create a batch of procedures to execute, I first create a new Job type function, then make a new procedure{}, add its details, and place this procedure in an array of pointers to procedures. Then I enqueue this batch of procedures into the job queue.
type Server struct { // ... procedures: make(chan utils.Queue[[]job], 100), // ...}updateGenerationsProc := &procedure{ name: "update-generations", exec: s.updateGenerations(i, ng),}
evolveProcs := jobs { // ... updateGenerationsProc, // ...}
q, _ := utils.NewStaticFixedQueue[jobs](1)_ = q.Enqueue(evolveProcs)
err := utils.SendWithContext(ctx, s.procedures, q)As per last post, a process jobs function is launched in a separate go routine and processes jobs. This was also updated to accommodate this new job interface.
func (s *ConlangServer) ProcessJobs(ctx context.Context) { for procs := range s.procedures { for p, err := procs.Dequeue(); err == nil; p, err = procs.Dequeue() { for _, j := range p { select { case <-ctx.Done(): s.logger.Warn("Processing context cancelled") return default: err = j.do(ctx) if err != nil { s.errs <- err return } } } } }}So with these two fixes implemented there was no longer any issue with syncrhonization and procedures.
More Ollama
Ollama was not working on the machine. I kept receiving a 404 error from the API whenever I’d make a local request. So in a rush, I rewrote the Ollama adapter I created to also accept streaming requests, as well had an optional client mode parameter that switched between the Ollama client and the HTTP client I wrote myself. The issue was that the model was not on the production machine I was using. Once I changed the model in the code to the one that was actually installed, qwen3:30b and NOT qwen30:a3b, it worked.
The final setup
With the two fixes implemented, this is what the final setup looked like: